金•品•服•务•器
专注于中国特种计算机应用解决方案



 4008-189-189
4008-189-189

金•品•服•务•器
专注于中国特种计算机应用解决方案
4008-189-189
时间:2025-07-28 14:40:58
背景
近年来,人工智能领域迎来“大模型革命”,以GPT、LLaMA为代表的大语言模型(LLM)在自然语言理解、内容生成、逻辑推理等方面展现出强大能力,成为推动产业智能化升级的核心引擎。然而,传统国际大模型依赖境外访问方式(如VPN)及付费使用模式,应用门槛较高。2025年1月 DeepSeek-R1的发布彻底改变了这一局面,性能比肩GPT-4,支持本地化部署,用户的关键数据无需上传云端,保障数据安全的同时大幅降低使用门槛。
用户痛点:
1. DeepSeek 服务器的硬件配置应如何选择?
2. 服务器部署DeepSeek大模型后应如何使用?如何发挥大模型的能力?
3. 受美国商务部对NVIDIA GPU的禁售限制,是否可采用国产GPU进行替代?
解决方案
金品 KG4208-H74 是一款国产化服务器,搭载两颗 48 核国产 C86 处理器及 8 张国产 GPU 加速卡(单卡显存 64GB,BF16 算力 240 TFLOPS),整机 BF16 算力达 1920 TFLOPS。该服务器预装国产麒麟 V10 操作系统、开源深度学习框架和 DeepSeek-R1-Distill-Llama-70B 大模型,可支持 170 个用户并发访问,满足 2000 人规模企业的应用需求。

金品KG4208-H74国产服务器
方案特点:
1. 金品 KG4208-H74 服务器深度适配国产 GPU 加速卡、开源 VLLM 框架及 DeepSeek-R1-Distill-Llama-70B大模型,通过软硬件协同优化,整机吞吐量可达 6700 Token/s,有效解决用户选型困难。
2. 金品 KG4208-H74 大模型一体机预装国产麒麟操作系统,部署 DeepSeek-R1-Distill-Llama-70B 大模型,并预置金品自研知识库系统。用户上传企业私有知识后,即可利用大模型进行本地化问答,有效规避云端数据泄露风险。该方案实现软硬件一体化本地部署,私有知识库问答准确率超过 90%。
3. 金品 KG4208-H74 实现软硬件全栈国产化,确保自主可控。其采用国产海光 C86 架构处理器,在满足国产化要求的同时具备优异的软件兼容性与强劲性能;搭载国产 GPU 加速卡,提供高达 1920 TFLOPS(BF16)的算力,在大模型推理场景下性能可达 NVIDIA A100 的 80%,处于国内领先水平。
金品KG4208-H74大模型一体机系统架构:
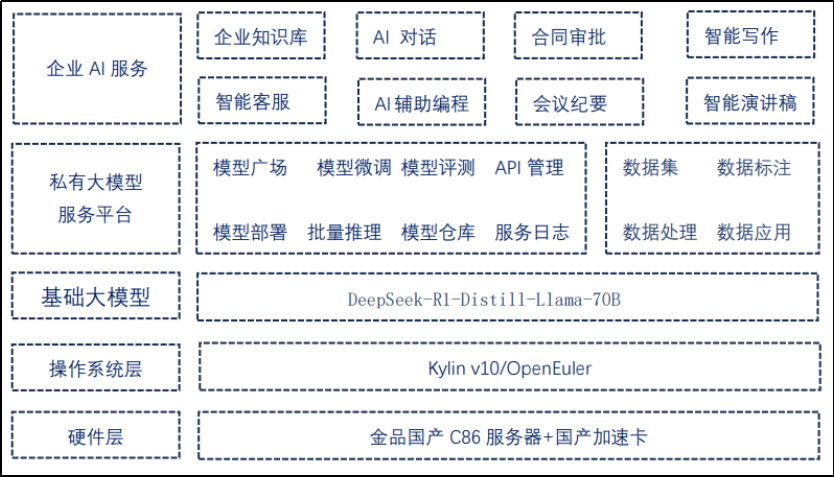
客户收益
1. 开箱即用:
预装国产麒麟操作系统、DeepSeek-R1 大模型及自研知识库系统,免去复杂环境部署;
支持企业私有数据一键上传,分钟级构建专属AI问答能力,大幅降低技术门槛。
2. 性能优化,高准确率:
软硬件协同优化实现 6700 Token/s 高吞吐量,响应速度提升 40% 以上;
私有知识库问答准确率 超 90%,满足合同审批、智能客服等高精度业务需求。
3. 自主可控,安全合规:
全栈国产化硬件(海光 C86 处理器 + 国产 GPU)及操作系统,彻底规避供应链风险;
数据本地化处理,敏感业务零上云,100% 符合等保 2.0/数据安全法要求。
4. 高效扩展,降本增效:
单机支持 170 用户并发,满足 2000 人规模企业全场景应用(如智能写作、会议纪要生成);国产 GPU 算力达 NVIDIA A100 的 80%,推理成本降低 50%,TCO 下降 35%。
