金•品•服•务•器
专注于中国特种计算机应用解决方案



 4008-189-189
4008-189-189

金•品•服•务•器
专注于中国特种计算机应用解决方案
4008-189-189
时间:2025-12-30 09:56:21
当前,以DeepSeek为代表的AI大模型正以前所未有的速度进化,其核心能力已从通用的自然语言处理,广泛渗透至金融风控、医疗诊断、工业质检以及智能客服等关键垂直领域。这些模型凭借强大的涌现能力,能够处理复杂的逻辑推理、长上下文理解和高精度专业任务,成为企业智能化转型的核心引擎。
然而,将如此强大能力“落地”到实际业务场景中,首先面临的是一道严峻的硬件门槛——海量显存需求。大模型的参数规模直接决定了其能力上限,也对其运行的硬件显存提出了苛刻要求。模型参数必须完整加载到GPU的显存中才能进行高效计算,这使得显存容量成为大模型部署不可逾越的刚性指标。
以DeepSeek-R1推理模型为例:

对于医疗、交通、能源、金融等关键行业,数据是最核心的资产之一,因此安全和自主可控是部署大模型的第一考量。同样这些行业应用需要解决复杂且专业的问题,比如:医疗行业,接入大模型需要处理病例、影像报告、药物研发等,对大模型的精准度要求较高。所以行业大模型行业落地,首先是安全可控,其次是对模型的参数量,即能力较高要求。
目前大模型的行业落地都选择私有化部署,实现数据不出域,安全可控。而私有化部署带来的问题就是不能及时在线更新大模型,所以在首次部署时选择最大参数量的模型(DeepSeek-R1 671B), 参数量越大显存需求就越大,带来硬件采购成本的上升,基于现状金品计算机推出KG6208-V5 服务器,2台即可部署满血版(671B)DeepSeek, 加速大模型的行业落地
金品KG6208-V5 服务器特点:
l支持8张NVIDIA RTX Pro 6000 96GB显卡,单机显存768GB,两台可部署DeepSeek满血版;
l整机14个风扇,冷热双风道极致设计,排除前后卡尾气效应,突破散热极限。
lCPU/GPU独立风道设计:上4U GPU散热与下2U CPU散热互相独立;
lCPU/GPU液冷设计:支持冷板式液冷,降低散热能耗,PUE≤1.25;
l最大支持8电源:4+4冗余,提高供电安全性;
l最大支持12LFF硬盘,最大支持4NVME,存储扩展性强;

金品KG6208-V5 NCCL Allto aLL带宽20.3GB/秒;

金品KG6208-V5 NCCL AllReduce,平均性能24.39GB/秒。
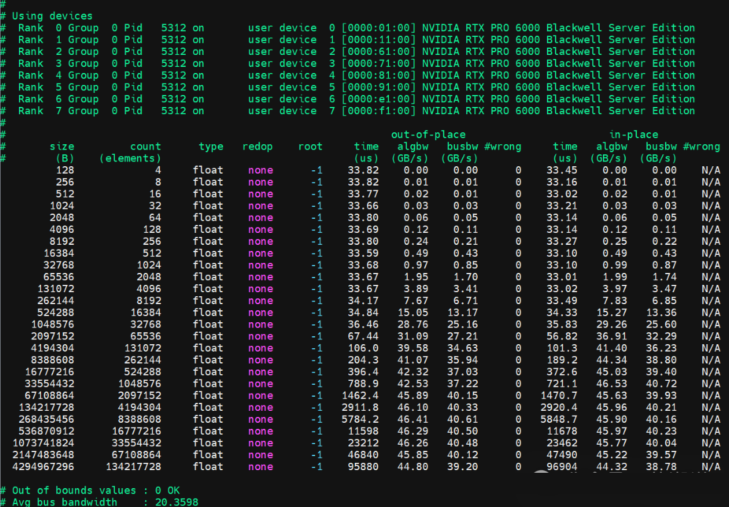
实战部署:
2台金品KG6208-V5 服务器通过200Gb/s 双链路互联,总显存1536GB部署DeepSeek-R1 671B 满血版,支持100个用户并发。
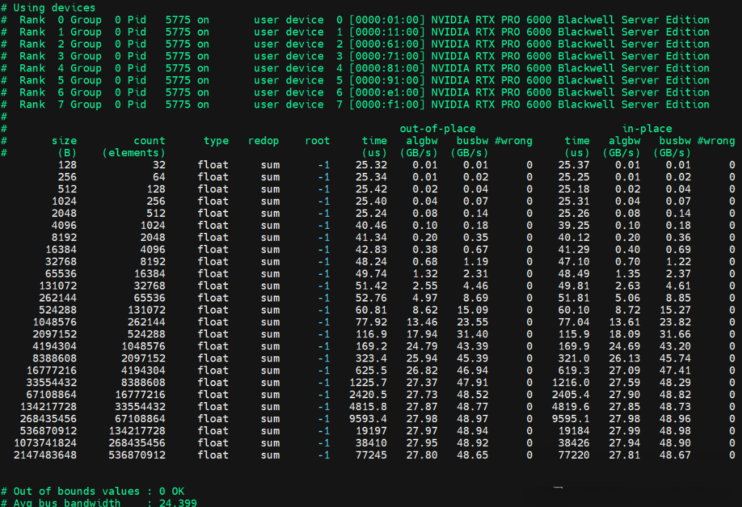
方案特点:
l最优成本:选用 2 台金品 KG6208-V5 服务器部署满血版 DeepSeek,相较 2 台 8 卡 H100 80G 服务器,采购成本直降 2/3,以高性价比达成成本最优化目标。
l高性能:单卡 96GB 超大显存可容纳更多模型参数,保障大模型稳定运行;搭配 PCIe5.0 接口与 200Gb 高速互联,大幅提升 GPU 卡间协同效率,降低传输延迟,充分发挥硬件最高性能。
l丰富的配置:金品 KG6208-V5 服务器支持多种配置,可部署DeepSeek、Qwen、GLM等多种类不同参数量的大模型。
