金•品•服•务•器
专注于中国特种计算机应用解决方案



 4008-189-189
4008-189-189

金•品•服•务•器
专注于中国特种计算机应用解决方案
4008-189-189
时间:2026-01-16 16:50:30
当前,以DeepSeek、豆包、千问等为代表的大语言模型,已凭借其强大的通用能力构建起全新的智能交互范式,成为数字时代的核心生产力工具之一。这些模型经过海量通用数据的训练,能够轻松应对日常沟通、信息检索、逻辑推理、文案创作等多元场景, 无论是生成条理清晰的商务邮件、解读复杂的公共政策文本,还是搭建简易的智能问答系统,都能展现出媲美甚至超越人类平均水平的表现。
然而,通用能力的强大,恰恰凸显了其在垂直行业应用中的核心短板——专业知识储备的不足。尽管大模型涵盖了海量公开领域的常识性知识,但面对医疗、金融、法律、高端制造等高度专业化的领域,其表现往往力不从心。造成专业知识不足的根本原因是,这些专业知识是在企业发展过程中积累下来的宝贵数据,是企业的核心资产,对外不公开,大模型在训练时无法获取到。
大模型要真正实现行业落地,核心前提是具备扎实的专业领域知识,要为大模型赋能行业专业能力,主要有两种路径:
其一,为大模型外挂行业知识库,也就是常说的RAG 技术。若将大模型的通用能力比作一名 “大学生”,那么 RAG 就如同为这名大学生配备了一套完整的行业专业资料库。当用户提出具体问题时,模型可通过检索资料库中的内容,结合自身通用能力给出解答。
其二,开展大模型微调。这种方式是将行业专业知识直接 “投喂” 给大模型,让大模型学习行业专业知识,本质上是实现了模型能力的跃升 —— 相当于将 “大学生” 培养成独当一面的 “行业专家”。
显然,相较于外挂知识库的辅助式方案,微调更能从根本上提升大模型的行业适配能力,最终落地效果也更为出色。
“大模型微调”让其学习新的行业专业知识,硬件需要具备强大的AI算力服务器和丰富的模型微调经验。 “金品计算机”做为AI服务器与解决方案的领导者,为了加速大模型行业落地,帮助企业快速数字化转型,利用AI大模型提升工作效率,推出了KG6208-V5微调服务器,支持700亿参数量推理和320亿参数量模型微调。
金品KG6208-V5微调服务器:

金品KG6208-V5硬件实力:
旗舰GPU配置:8张RTX5090赋能极致算力,作为方案核心算力支撑,KG6208-V5服务器原生支持8张NVIDIA RTX5090显卡,单卡32GB显存,整机显存容量达256GB,远超DeepSeek-R1 32B模型FP16精度下的80GB显存需求,可轻松承载模型加载与微调运算。同时,RTX5090依托Blackwell架构优势,在AI计算场景下吞吐效率较前代提升显著,搭配Unsloth等优化框架,可实现微调速度翻倍、显存占用降低70%的效果,大幅缩短微调周期。
硬件架构优化:多维度保障微调稳定性
协同效率:搭载PCIe 5.0接口,NCCL AllReduce平均性能达24.39GB/秒,卡间数据传输延迟极低,确保8张RTX5090高效协同,避免算力浪费;
散热设计:采用CPU/GPU独立风道+冷热双风道设计,14个高转速风扇搭配可选冷板式液冷,PUE≤1.25,有效解决多卡满负载运行的散热难题,保障微调过程持续稳定;
供电与存储:支持4+4冗余电源设计,供电稳定性拉满;最大支持12LFF硬盘+4NVME,满足微调过程中海量数据集的存储与高速读取需求。
金品KG6208-V5适配DeepSeek-R1 32B微调全流程
方案适配性:精准匹配32B级模型微调需求
金品KG6208-V5服务器针对DeepSeek-R1 32B模型特性做专项优化,无需额外硬件扩展即可实现模型高效微调。无论是LoRA微调还是动态量化微调,均能完美适配,同时兼容Unsloth、Llama-factory等主流微调框架,支持4bit/8bit量化加载,用户可根据数据集规模与精度需求灵活调整方案,平衡性能与效率。
微调核心优势:从速度、成本到稳定性的全面领先
高速微调:8张RTX5090协同运算,搭配RTX5090的AI算力优势,DeepSeek-R1 32B模型微调速度较传统4卡服务器提升80%以上,原本需24小时的微调任务可压缩至12小时内完成;
成本优化:相较采用H100显卡的服务器方案,采购成本直降2/3,同时依托高效能效设计,运行能耗降低30%,长期使用成本优势显著;
灵活扩展:支持单台部署满足32B模型微调,多台通过200Gb/s双链路互联可拓展至671B级大模型部署,适配企业从中小参数量模型微调到大模型全量训练的全周期需求。
软件生态兼容:无缝对接主流微调工具链
方案全面兼容PyTorch、TensorFlow等深度学习框架,支持Unsloth动态量化、Flash Attention 2等优化技术,无需修改代码即可实现从本地实验到服务器集群微调的无缝迁移。同时适配vLLM、Open-WebUI等部署工具,微调完成后可直接对接企业业务系统,实现“微调-部署-应用”全流程闭环。
实站DeepSeek 32B微调参数设定:
微调结果分析:
Epoch: 训练周期:3轮;
Num_input_tokens_seen: 模型在训练中已经处理了约 54.1 万个输入 token;
Total_flos: 总浮点计算量;
Train_loss: 训练损失数1.59,数值越低说明模型在训练集上的拟合效果越好。
Train_runtime: 训练耗时。
Train_samples_per_second:每秒约处理9.334个训练样本;
Train_steps_per_second: 每秒完成约0.299个训练步骤;
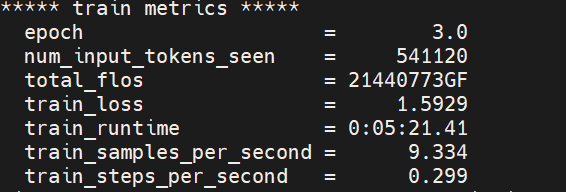
第 3 轮 epoch 训练正常,效率符合 LoRA 微调 32B 模型的预期,训练损失处于合理的水平。
典型行业应用场景
企业知识库微调:金融、政务领域基于DeepSeek-R1 32B模型微调专属知识库,KG6208-V5可支持海量文档数据导入与高效微调,实现精准问答与智能检索;
垂直领域适配:医疗、工业场景下,针对专业数据集微调模型,服务器稳定算力保障模型快速学习行业术语与逻辑,提升任务准确率;
科研与教育:高校、科研机构用于32B级模型微调实验,高性价比方案降低科研成本,同时高效算力加速研究进程。
