金•品•服•务•器
专注于中国特种计算机应用解决方案



 4008-189-189
4008-189-189

金•品•服•务•器
专注于中国特种计算机应用解决方案
4008-189-189
时间:2026-03-26 15:50:11
在大模型训练、深度学习推理、高性能计算等AI场景全面爆发的当下,服务器硬件的算力优化早已跳出“单纯堆核心、加显存”的浅层思路,转而聚焦数据传输效率与硬件互联架构的核心打磨。AI服务器想要实现算力高效释放,离不开CPU、GPU、内存、存储、高性能网卡等组件的协同运转,而串联起所有硬件的关键枢纽,正是PCIe(高速串行计算机扩展总线)技术。
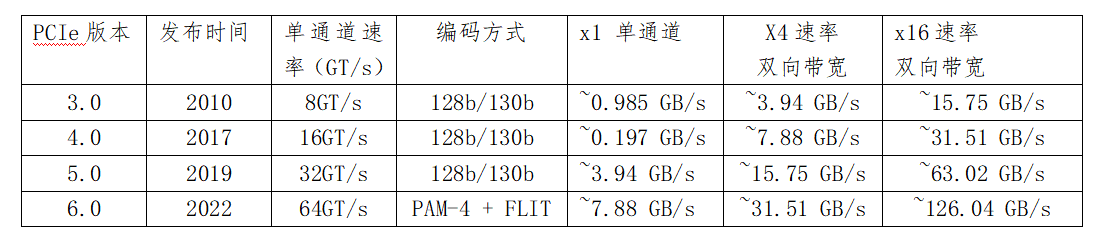
先了解一下PCIe的演进历史:
用户输入的 Prompt 文本先由 CPU 完成分词、向量化与请求调度预处理,再通过 PCIe 总线将向量数据送入多卡 GPU 显存中;随后 8 张 GPU 以张量并行模式协同工作,基于预加载的模型权重进行逐层前向推理计算,同时持续生成并维护对话所需的 KV Cache 缓存数据;在逐 Token 生成过程中,GPU 之间会频繁同步特征与结果数据,当单轮 Token 生成完毕后,再经由 PCIe 将计算结果传回 CPU 进行解码与后处理,最终输出完整文本回复。整个流程中,数据在 CPU 内存与 GPU 显存之间、多 GPU 之间高频交互,KV Cache 读写、权重分片读取、多卡同步通信均依赖高速传输通道,任何环节的带宽不足或延迟过高,都会直接导致首 Token 响应变慢、并发吞吐量下降,甚至出现推理卡顿。
大模型推理采用PCIe 5.0必要性:
1. 相比PCIe 4.0,PCIe 5.0 x16通道双向带宽翻倍,解决推理传输瓶颈:
2. 高并发承载:承接海量双向数据,减少排队闲置,提升整机吞吐量
3. 长上下文适配:实现KV Cache毫秒级调度,杜绝卡顿溢出
4. 低延迟优化:压缩数据搬运耗时,缩短首Token响应速度
5. 多卡协同:保障8卡并行数据同步,避免算力浪费
目前主流的GPU/NPU计算卡都是基于PCIe 5.0规范设计,比如:NVIDIA H100、RTX 5090、RTX 6000 PRO等,选择AI服务器时也要选支持PCIe 5.0带宽的服务器,因为在大模型训练、推理阶段GPU卡之间有大量的通讯,PCIe带宽越高通讯越快,计算性能就越好。
再来看一下CPU支持PCIe的情况,以Intel Xeon 6530举例,单颗支持80个PCIe 5.0 Lanes, 双路达到160个PCIe 5.0 lanes,如何分配这160个lanes其中大有学问,以下就以”金品KG4208-V4”服务器进行分析。

“金品KG 4208-V4 服务器”分为PCIe直连版本和Switch版本, 今天就介绍PCIe直连版本,它是一款4U 双路8卡GPU/NPU服务器,CPU通过PCIe 5.0通道直连GPU,构成大带宽、低时延;适用于大模推理、高性能计算等场景。
“金品KG4208-V4服务器”采用2颗Intel Xeon 6530 处理器, 支持8个双宽GPU(H200/H100/A100/4090)、同时支持1个PCIe 5.0 x16和1个x8 或 3个PCIe 5.0 x8;
同时支持1个PCIe 4.0 x8 OCP网卡和2块PCIe 5.0 NVMe U.2 硬盘;把PCIe信号全部拉满,高效利用并合理分配。
PCIe链路拓扑分析:
“金品KG4208-V4服务器”核心部件是主板、GPU扩展板、硬盘背板三部分组成;主板上共有21个MCIO接口,每个MCIO接口是PCIe x8 ,总计168个PCIe lane; 其中20个MCIO,来自两颗Intel Xeon处理器,另1个MCIO来自CPU2 DMI连接, 用于OCP网卡信号;处理器直出的20个MICO其中16个连接到扩展板的GPU专用插槽, 支持8个双宽GPU;1个连接到硬盘背板支持2块NVMe U.2硬盘、另3个连接到GPU扩展板构成1个x16 + 1个x8或3个x8 做网卡、RAID卡扩展。
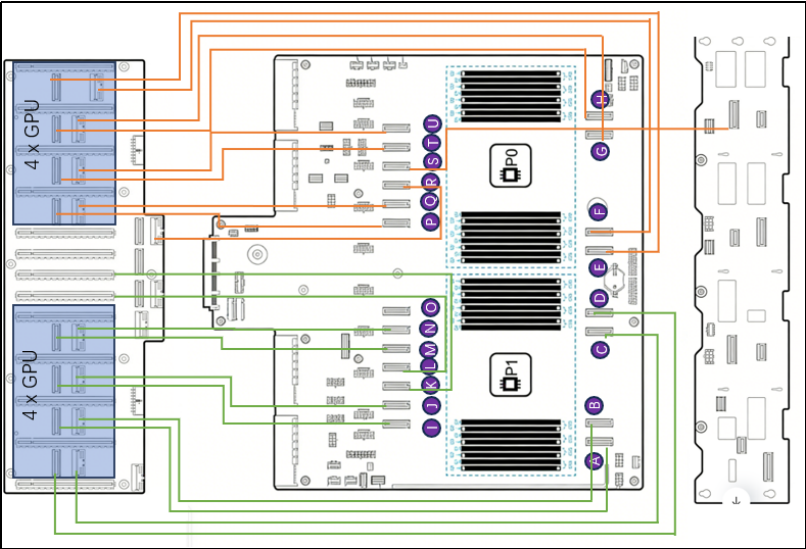
设计理念及特点:
1. 整机严格遵循 PCIe 5.0 标准架构,确保每一张 GPU 均独享全速 x16 通道,无带宽争
抢、无资源挤占,最大化释放 CPU 与 GPU 间的双向数据传输效率,彻底解决大流量数据搬运瓶颈。
2. 采用高性能 CPU 直连 GPU 的极简拓扑路径,天然规避 Switch 芯片引入的额外转发延
迟与数据抖动,精准适配大模型高频、低时延的推理业务特征,显著缩短首 Token 响应时间。
3. 前置2个 NVMe U.2 高速固态硬盘,灵活支持 RAID 0 高速读写或 RAID 1 安全冗余配
置,大幅提升 TB 级大模型权重文件从本地存储至 GPU 显存的极速加载能力,根除低速硬盘 IO 带来的启动与调度瓶颈。
4. 通过合理的分配PCIe资源, 使整机可配置 400Gb/s ROCE 无损网络网卡,满足集群节
点间超高带宽模型分片与增量通信;以及为系统盘组建 RAID 1 镜像,保障业务 7×24 小时稳定不宕机。
大模型推理的性能上限,不只取决于 GPU 算力,更由PCIe 带宽与互联架构直接决定。PCIe 5.0 已成为大模型推理的必备基础,而金品 KG4208V4 PCIe 直连版凭借全链路 PCIe 5.0、CPU 直连低延迟、通道最优分配、高速存储与高可靠设计,成为高并发、低时延、长上下文大模型在线推理的理想硬件平台,是企业部署 AI 推理服务的优选服务器。
